


 视频会议高清流畅的音视频会议
视频会议高清流畅的音视频会议 元宝纪要·AI托管智能提炼关键内容,实时掌握会议进展
元宝纪要·AI托管智能提炼关键内容,实时掌握会议进展 AI小助手一站式智能会议助手
AI小助手一站式智能会议助手 网络研讨会大型营销、培训、研讨会议解决方案
网络研讨会大型营销、培训、研讨会议解决方案
 会议室(Rooms)如意会议室
会议室(Rooms)如意会议室 会议室连接器(MRA)完美兼容SIP/H.323
会议室连接器(MRA)完美兼容SIP/H.323 腾讯天籁inside会议室音频解决方案
腾讯天籁inside会议室音频解决方案
 开放平台提供丰富的接入方式
开放平台提供丰富的接入方式 应用市场海量会议扩展应用
应用市场海量会议扩展应用
 专业服务会议护航、Rooms部署等全方位服务
专业服务会议护航、Rooms部署等全方位服务
 证券
证券 金融
金融 医药
医药 医疗
医疗 教育
教育 零售
零售 能源
能源 出行
出行 工业制造
工业制造 法院
法院
 招聘面试
招聘面试- 金融路演
- 数字营销
- 会议室预订
- 医药科室会
 培训
培训- 远程调度





 帮助中心寻找开会秘籍
帮助中心寻找开会秘籍- 视频教学视频演示开会技巧
- 体验中心·组织提效篇多账号协同更高效
- 体验中心·会议安全篇保护企业数据资产


- 展会活动发现精选热门活动
 新闻中心获取最新动态
新闻中心获取最新动态 交流社区用户交流中心
交流社区用户交流中心

 合作伙伴携手共创会议生态
合作伙伴携手共创会议生态- 伙伴招募成为会议合作伙伴共创会议生态
- 代理查询快速查找本地认证代理商获取服务
- 接入开放平台全方位接入/集成应用解决方案参考
- 技术论坛实时技术讨论沟通平台




 联系销售获取会议解决方案
联系销售获取会议解决方案 专家支持服务为您提供全方面的会议保障
专家支持服务为您提供全方面的会议保障- 预约演示提供全产品线上演示

AI+16麦拾音、多模态智能定位发言人腾讯天籁inside3.0来了!
来玩个游戏,猜猜会议室里是谁在说话?
在大型会议室里,混响挑战严重,光是要听清有人在说话已经很难。况且,由于会议室里多人并坐,很难分清谁是当前说话人,要准确分辨出是会议室里的谁在说话,跟他产生对话感,那便是难上加难。
而对话感,深深影响着沟通的效率和质量。
为了应对上述挑战,腾讯天籁inside迎来了全新3.0升级,在腾讯AI Lab多项技术加持下,推出了16mic多模态人像分割解决方案。业界领先的AI+16阵列麦拾音矩阵+音视频多模态识别算法,仿佛为会议室同时装上了“顺风耳与千里眼”,为会议室体验带来了三大升级:
首发智能“千里眼”
基于音视频多模态AI算法,精准区分、定位会议室里的发言人,能够让他们时刻处于画面C位,让交流更专注、高效。
更灵敏的“顺风耳”
更大空间的远距离拾音,升级的去混响效果,让听感始终保持清晰、真实、自然。
特定区域的“专属麦克风”
具备智能音幕功能,让线上发言人可以始终只听到特定区域的声音,进一步减少大环境人声和噪声干扰。
顺风耳+专属麦克风+千里眼的全新亮眼组合,让我们一起来看看有多震撼?!
智能“千里眼”,让会议室发言人时刻被看到
现代化的会议室通常采用大面积的玻璃设计,混响非常严重,若采用传统的声源定位模式,在噪声和混响条件下,特别是当发言人空间方位相近时,就很难准确定位到当前发言人。
腾讯天籁inside在每一场会都会给每位发言人快速建立人声合一的档案,结合多模态AI算法,就能够在众多的会议室参会者中准确识别出当前发言人,即便距离相近、发言人侧对/背对摄像头、亦或是移动中,都能牢牢锁定。
*腾讯会议与腾讯天籁不会储存发言人的声纹。
更优秀的去混响能力,大型会议空间里的“顺风耳”
会议空间越大,拾音就越困难。
业界领先的AI+16阵列麦的拾音矩阵,具备了更优秀的去混响能力,有效解决超大型空旷会议空间下、语音可懂度低的问题,无论我们在房间的任何位置发言,也能像面对面说话一样,清晰、真实、自然。
超强的去混响能力搭配上自动增益算法,无论线下发言人距离屏幕远近,线上都能听到均衡一致的清晰声音。而且天籁16麦音频方案进一步优化了降噪模型,让线上参会者不受各种噪声干扰。
智能音幕重磅上线,打造特定区域的“专属麦克风”
许多公司都贴心打造了灵活的开放办公空间,当我们在这样的区域里开启线上会议时,经常会收到各种背景噪声或者人声干扰。
新一代的腾讯天籁inside方案具备了智能音幕能力,可以建立起虚拟的音频屏障,相当于给区域内的参会者配上了专属麦克风,有效屏蔽区域外的噪声和人声干扰,就算区域外有人同时说话,也能在双讲情况下,清晰地屏蔽区域外的人声。而且,这个“专属麦克风”是支持实时调整方向的哦!灵活满足不同开放空间里的拾音需求。
当前3.0版本的腾讯天籁inside已经率先应用在了MAXHUB 视讯款V7及MAXHUB 视讯智真款会议平板上,我们也欢迎更多厂商一起合作。
我们也将提供全链路深度合作支持,从算法层、芯片层、硬件层到产品层,全方位护航产品研发,共同打造机智会议室音视频体验。
腾讯天籁inside能够实时计算出当前发言人及在场所有人的人脸轮廓和身体坐标位置,这些底层坐标,也会开放给合作厂商,进行个性化开发,定制发言人的画幅比例、多人对话时的切换速度、切换逻辑,以最佳视角展示发言人。
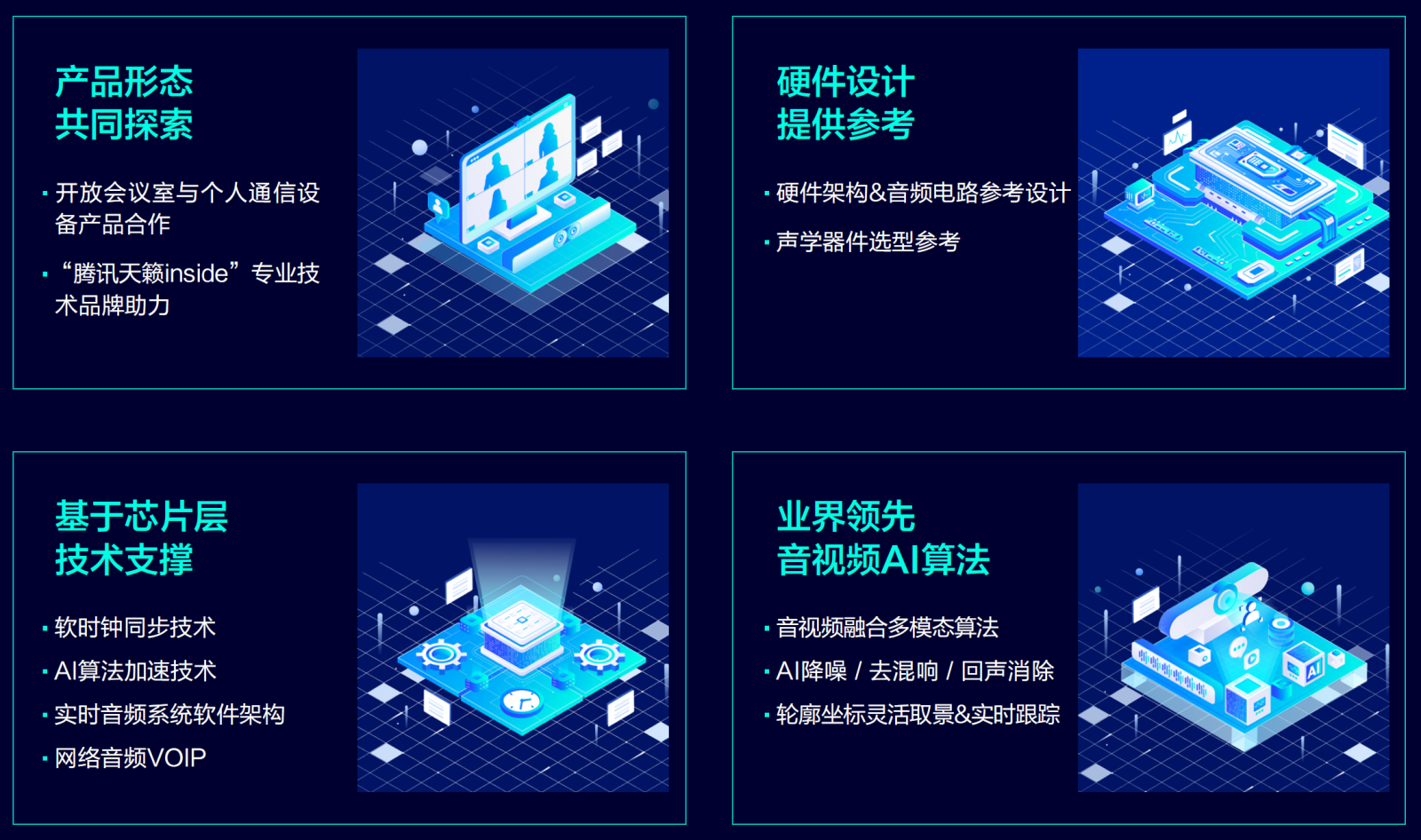
感兴趣的硬件厂商,欢迎通过下列方式联系我们哦!